
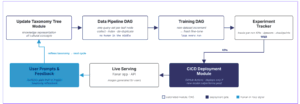
This work builds on top of a fundamental conviction that the development of production-grade ML-based systems starts after the first deployment of an initial model. The basic idea is that there is no way to comprehensively collect all relevant data possible to achieve a certain user-satisfaction-related metric but that it rather comes down to an effective and smart feedback loop that drives an ever improving model with increasing user satisfaction.
The solution uses industry-grade MLOps techniques including pipe-lining tools such as Airflow to elevate the development from a set of manual script invocations on heterogeneous hardware with strong need for human oversight and lack of failure recovery to a an automatically orchestrated execution of a set of processes with maximized resources efficiency and fault recovery capabilities for a scaled data acquisition and training.
The data-driven approach to improve the model requires solving a fundamental scientific challenge, namely that of determining the criterea for new data download and subsequent training based on the user logs and the user feedback. In this work we investigate different ways to solve this problem for example using an evolving taxonomy based data acquisition.
The solution we aim at is one that would enable resource-constrained institutions to build a tailored effective GenAI system without extensive bootstrapping and with maximal user-driven feedback. For more information, get in touch with @analnuaimihbku-edu-qa.